25Inference for linear regression with multiple predictors
In Chapter 8, the least squares regression method was used to estimate linear models which predicted a particular response variable given more than one explanatory variable. Here, we discuss whether each of the variables individually is a statistically discernible predictor of the outcome or whether the model might be just as strong without that variable. That is, as before, we apply inferential methods to ask whether a variable could have come from a population where the particular coefficient at hand was zero. If one of the linear model coefficients is truly zero (in the population), then the estimate of the coefficient (using least squares) will vary around zero. The inference task at hand is to decide whether the coefficient’s difference from zero is large enough to decide that the data cannot possibly have come from a model where the true population coefficient is zero. Both the derivations from the mathematical model and the randomization model are beyond the scope of this book, but we are able to calculate p-values using statistical software. We will discuss interpreting p-values in the multiple regression setting and note some scenarios where careful understanding of the context and the relationship between variables is important. We use cross-validation as a method for independent assessment of the multiple linear regression model.
The loans_full_schema data can be found in the openintro R package. Based on the data in this dataset we have created two new variables: credit_util which is calculated as the total credit utilized divided by the total credit limit and bankruptcy which turns the number of bankruptcies to an indicator variable (0 for no bankruptcies and 1 for at least 1 bankruptcies). We will refer to this modified dataset as loans.
Now, our goal is to create a model where interest_rate can be predicted using the variables debt_to_income, term, and credit_checks. As you learned in Chapter 8, least squares can be used to find the coefficient estimates for the linear model. The unknown population model can be written as:
Table 25.1: Summary of a linear model for predicting interest rate based on debt_to_income, term, and credit_checks. Each of the variables has its own coefficient estimate as well as a p-value.
term
estimate
std.error
statistic
p.value
(Intercept)
4.31
0.20
22.1
<0.0001
debt_to_income
0.04
0.00
13.3
<0.0001
term
0.16
0.00
37.9
<0.0001
credit_checks
0.25
0.02
12.8
<0.0001
The estimated equation for the regression model may be written as a model with three predictor variables:
Not only does Table 25.1 provide the estimates for the coefficients, it also provides information on the inference analysis (i.e., hypothesis testing) which is the focus of this chapter.
In Chapter 24, you learned that the hypothesis test for a linear model with one predictor1 can be written as:
if only one predictor, \(H_0: \beta_1 = 0.\)
That is, if the true population slope is zero, the p-value measures how likely it would be to select data which produced the observed slope (\(b_1\)) value.
With multiple predictors, the hypothesis is similar, however, it is now conditioned on each of the other variables remaining in the model.
if multiple predictors, \(H_0: \beta_i = 0\) given other variables in the model
Using the example above and focusing on each of the variable p-values (here we won’t discuss the p-value associated with the intercept), we can write out the three different hypotheses:
\(H_0: \beta_1 = 0\), given term and credit_checks are included in the model
\(H_0: \beta_2 = 0\), given debt_to_income and credit_checks are included in the model
\(H_0: \beta_3 = 0\), given debt_to_income and term are included in the model
The very low p-values from the software output tell us that each of the variables acts as an important predictor in the model, despite the inclusion of the other two. Consider the p-value on \(H_0: \beta_1 = 0\). The low p-value says that it would be extremely unlikely to see data that produce a coefficient on debt_to_income as large as 0.041 if the true relationship between debt_to_incomeand interest_rate was non-existent (i.e., if \(\beta_1 = 0\)) and the model also included term and credit_checks. You might have thought that the value 0.041 is a small number (i.e., close to zero), but in the units of the problem, 0.041 turns out to be far away from zero, it’s all about context! The p-values on term and on credit_checks are interpreted similarly.
Sometimes a set of predictor variables can impact the model in unusual ways, often due to the predictor variables themselves being correlated.
25.2 Multicollinearity
In practice, there will almost always be some degree of correlation between the explanatory variables in a multiple regression model. For regression models, it is important to understand the entire context of the model, particularly for correlated variables. Our discussion will focus on interpreting coefficients (and their signs) in relationship to other variables as well as the discernibility (i.e., the p-value) of each coefficient.
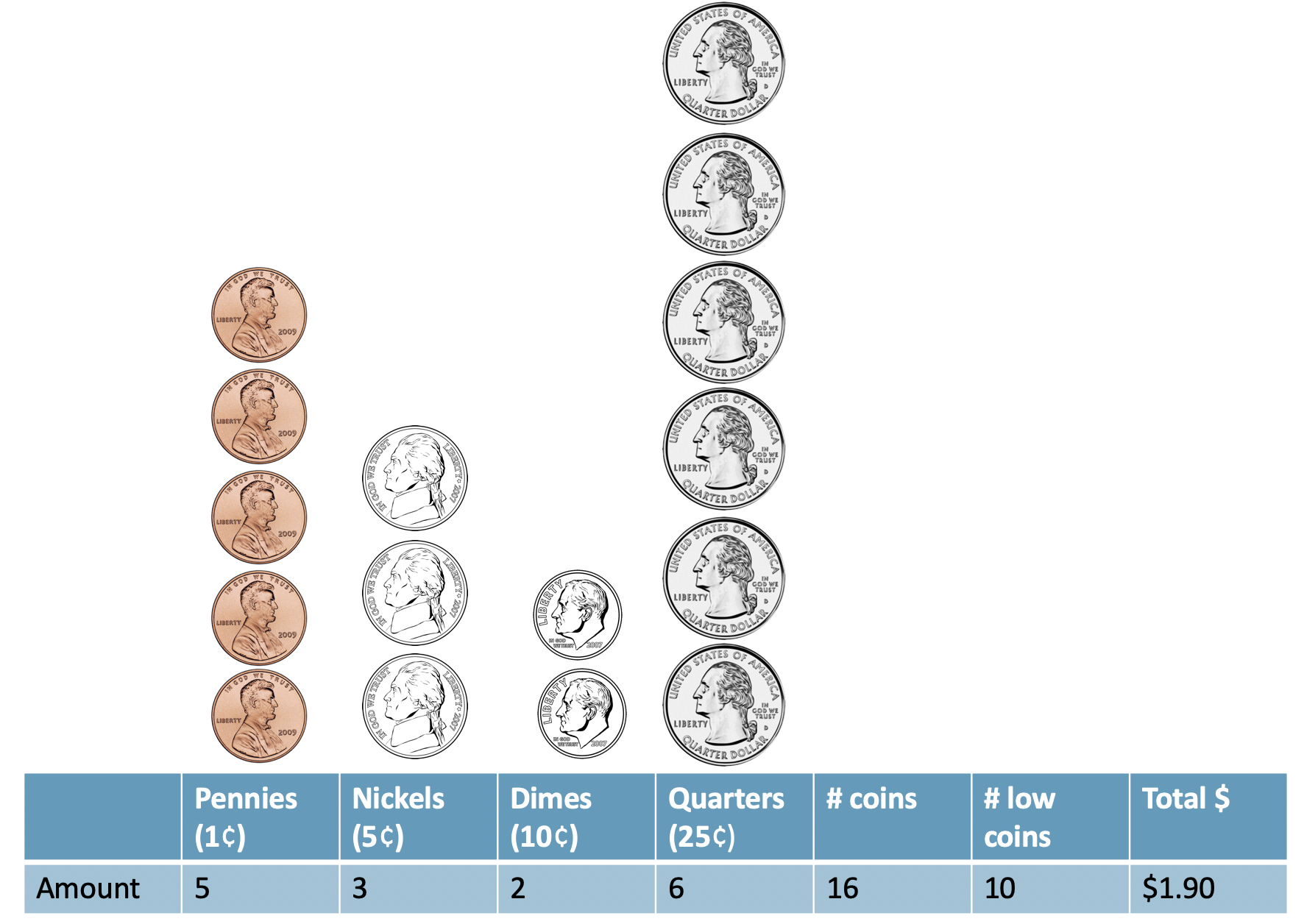
Consider an example where we would like to predict how much money is in a coin dish based only on the number of coins in the dish. We ask 26 students to tell us about their individual coin dishes, collecting data on the total dollar amount, the total number of coins, and the total number of low coins.2 The number of low coins is the number of coins minus the number of quarters (a quarter is the largest commonly used US coin, at US$0.25). Figure 25.1 illustrates a sample of U.S. coins, their total worth (total_amount), the total number_of_coins, and the number_of_low_coins.
Figure 25.1: A sample of coins with 16 total coins, 10 low coins, and a net worth of $1.90.
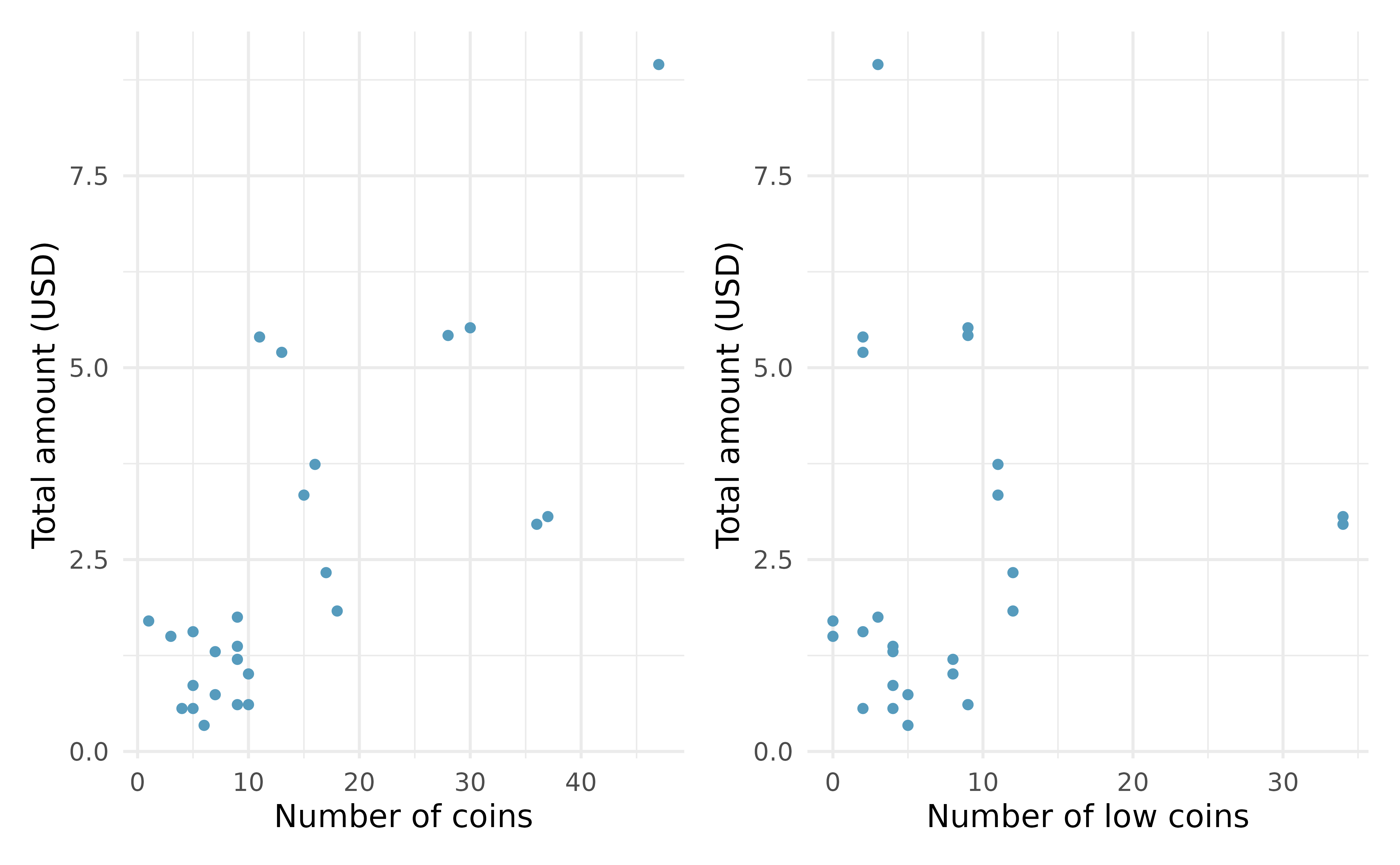
The collected data is given in Figure 25.2 and shows that the total_amount of money is more highly correlated with the total number_of_coins than it is with the number_of_low_coins. We also note that the total number_of_coins and the number_of_low_coins are positively correlated.
Figure 25.2: Plot describing the total amount of money (USD) as a function of the number of coins and the number of low coins. As you might expect, the total amount of money is more highly postively correlated with the total number of coins than with the number of low coins.
Using the total number_of_coins as the predictor variable, Table 25.2 provides the least squares estimate of the coefficient is 0.13. For every additional coin in the dish, we would predict that the student had US$0.13 more. The \(b_1 = 0.13\) coefficient has a small p-value associated with it, suggesting we would not have seen data like this if number_of_coins and total_amount of money were not linearly related.
Table 25.2: Linear model output predicting the total amount of money based on the total number of coins.
term
estimate
std.error
statistic
p.value
(Intercept)
0.55
0.44
1.23
0.2301
number_of_coins
0.13
0.02
5.54
<0.0001
Using number_of_low_coins as the predictor variable, Table 25.3 provides the least squares estimate of the coefficient is 0.02. For every additional low coin in the dish, we would predict that the student had US$0.02 more. The \(b_1 = 0.02\) coefficient has a large p-value associated with it, suggesting we could easily have seen data like ours even if the number_of_low_coins and total_amount of money are not at all linearly related.
Table 25.3: Linear model output predicting the total amount of money based on the number of low coins.
term
estimate
std.error
statistic
p.value
(Intercept)
2.28
0.58
3.9
0.0
number_of_low_coins
0.02
0.05
0.4
0.7
Come up with an example of two observations that have the same number of low coins but the number of total coins differs by one. What is the difference in total amount?
Two samples of coins with the same number of low coins (3), but a different number of total coins (4 vs 5) and a different total total amount ($0.41 vs $0.66).
Come up with an example of two observations that have the same total number of coins but a different number of low coins. What is the difference in total amount?
Two samples of coins with the same total number of coins (4), but a different number of low coins (3 vs 4) and a different total total amount ($0.41 vs $0.17).
Using both the total number_of_coins and the number_of_low_coins as predictor variables, Table 25.4 provides the least squares estimates of both coefficients as 0.21 and -0.16. Now, with two variables in the model, the interpretation is more nuanced.
A coefficient interpretation always indicates a change in one variable while keeping the other variable(s) constant.
For every additional coin in the dish while the number_of_low_coins stays constant, we would predict that the student had US$0.21 more. Re-considering the phrase “every additional coin in the dish while the number of low coins stays constant” makes us realize that each increase is a single additional quarter (larger samples sizes would have led to a \(b_1\) coefficient closer to 0.25 because of the deterministic relationship described here).
For every additional low coin in the dish while the total number_of_coins stays constant, we would predict that the student had US$0.16 less. Re-considering the phrase “every additional low coin in the dish while the number of total coins stays constant” makes us realize that a quarter is being swapped out for a penny, nickel, or dime.
Considering the coefficients across Table 25.2, Table 25.3, and Table 25.4 within the context and knowledge we have of US coins allows us to understand the correlation between variables and why the signs of the coefficients would change depending on the model. Note also, however, that the p-value for the number_of_low_coins coefficient changed from Table 25.3 to Table 25.4. It makes sense that the variable describing the number_of_low_coins provides more information about the total_amount of money when it is part of a model which also includes the total number_of_coins than it does when it is used as a single variable in a simple linear regression model.
Table 25.4: Linear model output predicting the total amount of money based on both the total number of coins and the number of low coins.
term
estimate
std.error
statistic
p.value
(Intercept)
0.80
0.30
2.65
0.0142
number_of_coins
0.21
0.02
9.89
<0.0001
number_of_low_coins
-0.16
0.03
-5.51
<0.0001
When working with multiple regression models, interpreting the model coefficients is not always as straightforward as it was with the coin example. However, we encourage you to always think carefully about the variables in the model, consider how they might be correlated among themselves, and work through different models to see how using different sets of variables might produce different relationships for predicting the response variable of interest.
Multicollinearity.
Multicollinearity happens when the predictor variables are correlated within themselves. When the predictor variables themselves are correlated, the coefficients in a multiple regression model can be difficult to interpret.
Although diving into the details are beyond the scope of this text, we will provide one more reflection about multicollinearity. If the predictor variables have some degree of correlation, it can be quite difficult to interpret the value of the coefficient or evaluate whether the variable is a statistically discernible predictor of the outcome. However, even a model that suffers from high multicollinearity will likely lead to unbiased predictions of the response variable. So if the task at hand is only to do prediction (and not to interpret coefficients), multicollinearity is likely to not cause you substantial problems.
25.3 Cross-validation for prediction error
In Section 25.1, p-values were calculated on each of the model coefficients. The p-value gives a sense of which variables are important to the model; however, a more extensive treatment of variable selection is warranted in a follow-up course or textbook. Here, we use cross-validation prediction error to focus on which variable(s) are important for predicting the response variable of interest. In general, linear models are also used to make predictions of individual observations. In addition to model building, cross-validation provides a method for generating predictions that are not overfit to the particular dataset at hand. We continue to encourage you to take up further study on the topic of cross-validation, as it is among the most important ideas in modern data analysis, and we are only able to scratch the surface here.
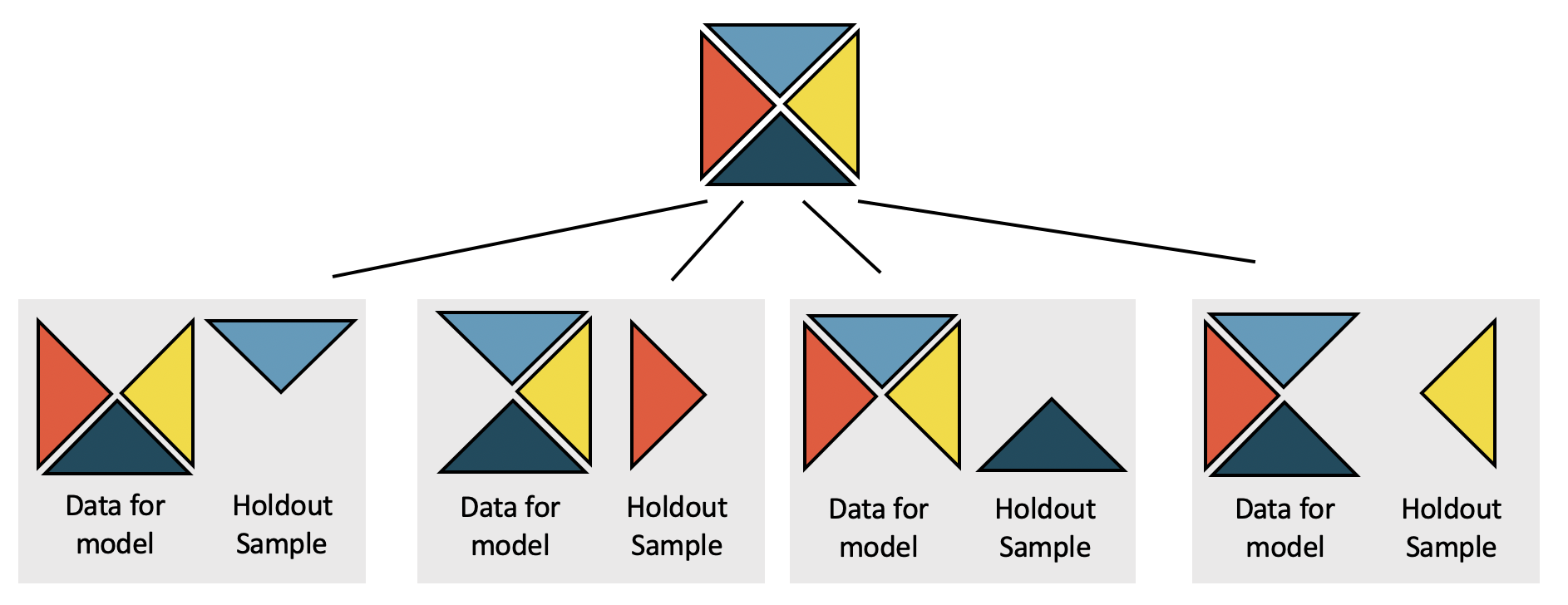
Cross-validation is a computational technique which removes some observations before a model is run, then assesses the model accuracy on the held-out sample. By removing some observations, we provide ourselves with an independent evaluation of the model (that is, the removed observations do not contribute to finding the parameters which minimize the least squares equation). Cross-validation can be used in many different ways (as an independent assessment), and here we will just scratch the surface with respect to one way the technique can be used to compare models. See Figure 25.3 for a visual representation of the cross-validation process.
Figure 25.3: The dataset is broken into k folds (here k = 4). One at a time, a model is built using k-1 of the folds, and predictions are calculated on the single held out sample which will be completely independent of the model estimation.
Our goal in this section is to compare two different regression models which both seek to predict the mass of an individual penguin in grams. The observations of three different penguin species include measurements on body size and sex. The data were collected by Dr. Kristen Gorman and the Palmer Station, Antarctica LTER as part of the Long Term Ecological Research Network. (Gorman, Williams, and Fraser 2014) Although not exactly aligned with this research project, you might be able to imagine a setting where the dimensions of the penguin are known (through, for example, aerial photographs) but the mass is not known. The first model will predict body_mass_g by using only the bill_length_mm, a variable denoting the length of a penguin’s bill, in mm. The second model will predict body_mass_g by using bill_length_mm, bill_depth_mm, flipper_length_mm, sex, and species.
Prediction error.
The predicted error (also previously called the residual) is the difference between the observed value and the predicted value (from the regression model).
The presentation below (see the comparison of Figure 25.5 and Figure 25.7) shows that the model with more variables predicts body_mass_g with much smaller errors (predicted minus actual body mass) than the model which uses only bill_length_g. We have deliberately used a model that intuitively makes sense (the more body measurements, the more predictable mass is). However, in many settings, it is not obvious which variables or which models contribute most to accurate predictions. Cross-validation is one way to get accurate independent predictions with which to compare different models.
25.3.1 Comparing two models to predict body mass in penguins
The question we will seek to answer is whether the predictions of body_mass_g are substantially better when bill_length_mm, bill_depth_mm, flipper_length_mm, sex, and species are used in the model, as compared with a model on bill_length_mm only.
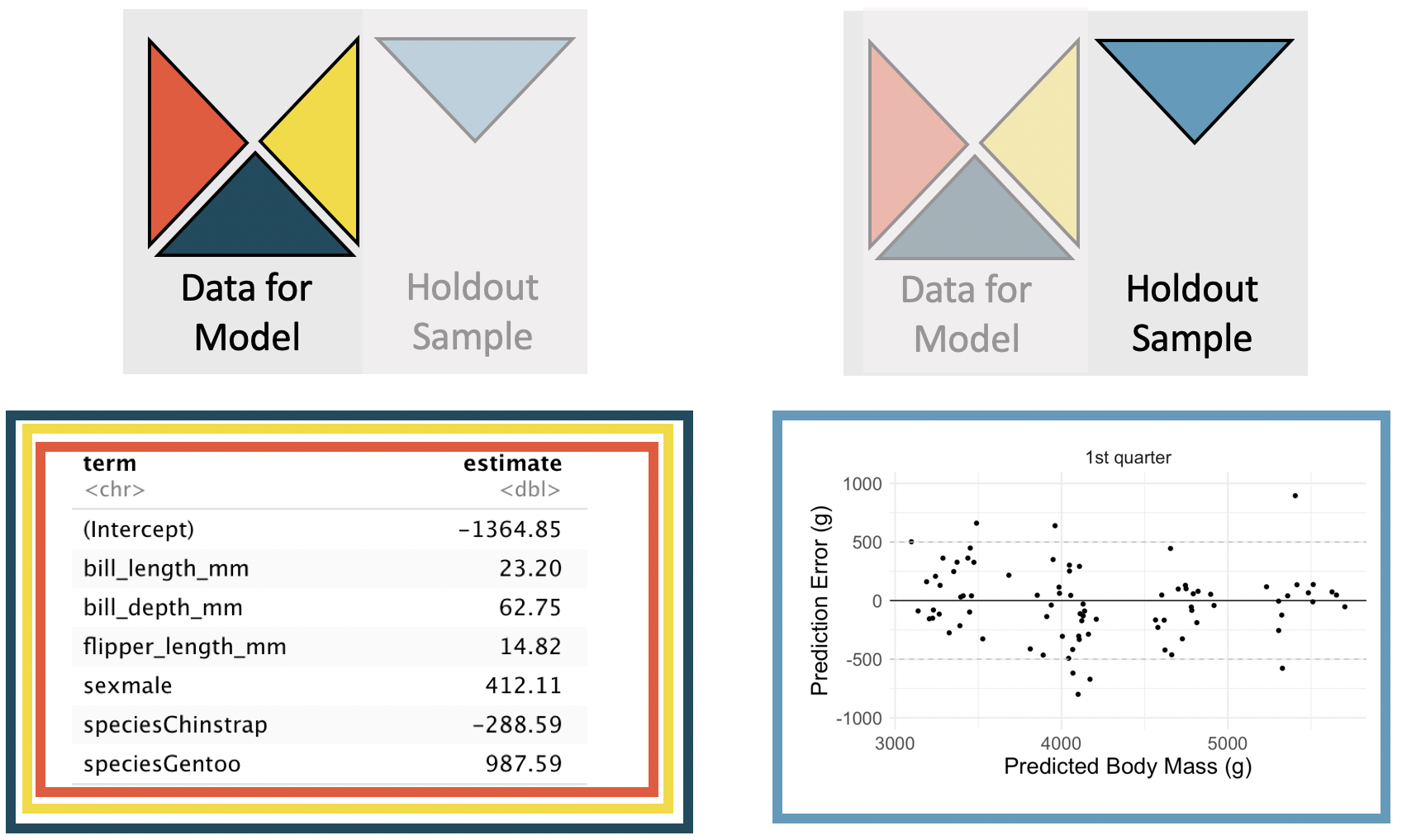
We refer to the model given with only bill_lengh_mm as the smaller model. It is seen in Table 25.5 with coefficient estimates of the parameters as well as standard errors and p-values. We refer to the model given with bill_lengh_mm, bill_depth_mm, flipper_length_mm, sex, and species as the larger model. It is seen in Table 25.6 with coefficient estimates of the parameters as well as standard errors and p-values. Given what we know about high correlations between body measurements, it is somewhat unsurprising that all of the variables have low p-values, suggesting that each variable is a statistically discernible predictor of body_mass_g, given all other variables in the model. However, in this section, we will go beyond the use of p-values to consider independent predictions of body_mass_g as a way to compare the smaller and larger models.
Table 25.6: The larger model: least squares estimates of the regression model predicting body_mass_g from bill_length_mm, bill_depth_mm, flipper_length_mm, sex, and species.
term
estimate
std.error
statistic
p.value
(Intercept)
-1461.0
571.31
-2.56
0.011
bill_length_mm
18.2
7.11
2.56
0.0109
bill_depth_mm
67.2
19.74
3.40
7e-04
flipper_length_mm
15.9
2.91
5.48
<0.0001
sexmale
389.9
47.85
8.15
<0.0001
speciesChinstrap
-251.5
81.08
-3.10
0.0021
speciesGentoo
1014.6
129.56
7.83
<0.0001
In order to compare the smaller and larger models in terms of their ability to predict penguin mass, we need to build models that can provide independent predictions based on the penguins in the holdout samples created by cross-validation. To reiterate, each of the predictions that (when combined together) will allow us to distinguish between the smaller and larger are independent of the data which were used to build the model. In this example, using cross-validation, we remove one quarter of the data before running the least squares calculations. Then the least squares model is used to predict the body_mass_g of the penguins in the holdout sample. Here we use a 4-fold cross-validation (meaning that one quarter of the data is removed each time) to produce four different versions of each model (other times it might be more appropriate to use 2-fold or 10-fold or even run the model separately after removing each individual data point one at a time).
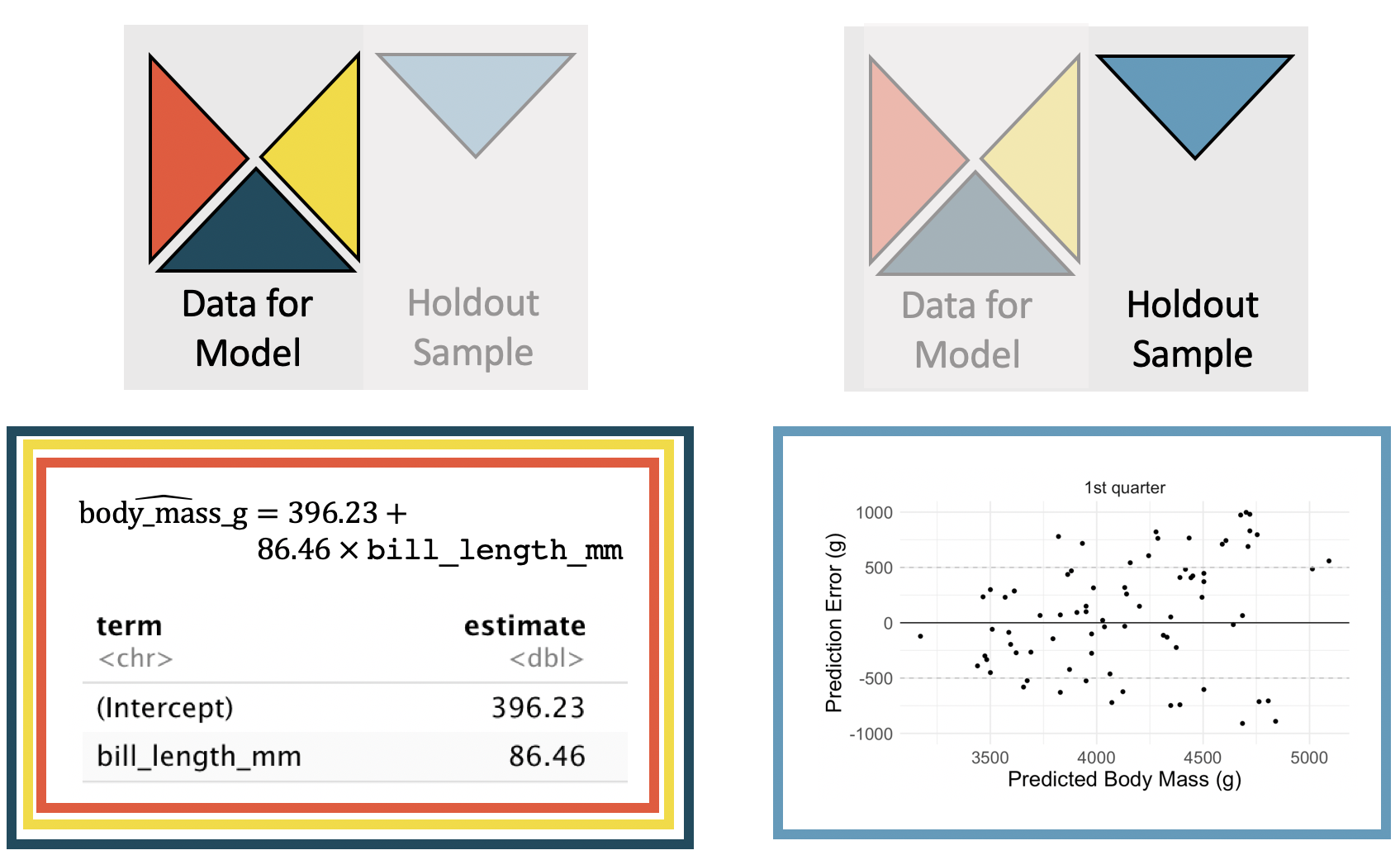
Figure 25.4 displays how a model is fit to 3/4 of the data (note the slight differences in coefficients as compared to Table 25.5), and then predictions are made on the holdout sample.
Figure 25.4: The smaller model. The coefficients are estimated using the least squares model on 3/4 of the dataset with only a single predictor variable. Predictions are made on the remaining 1/4 of the observations. The y-axis in the scatterplot represents the residual: true observed value minus the predicted value. Note that the predictions are independent of the estimated model coefficients.
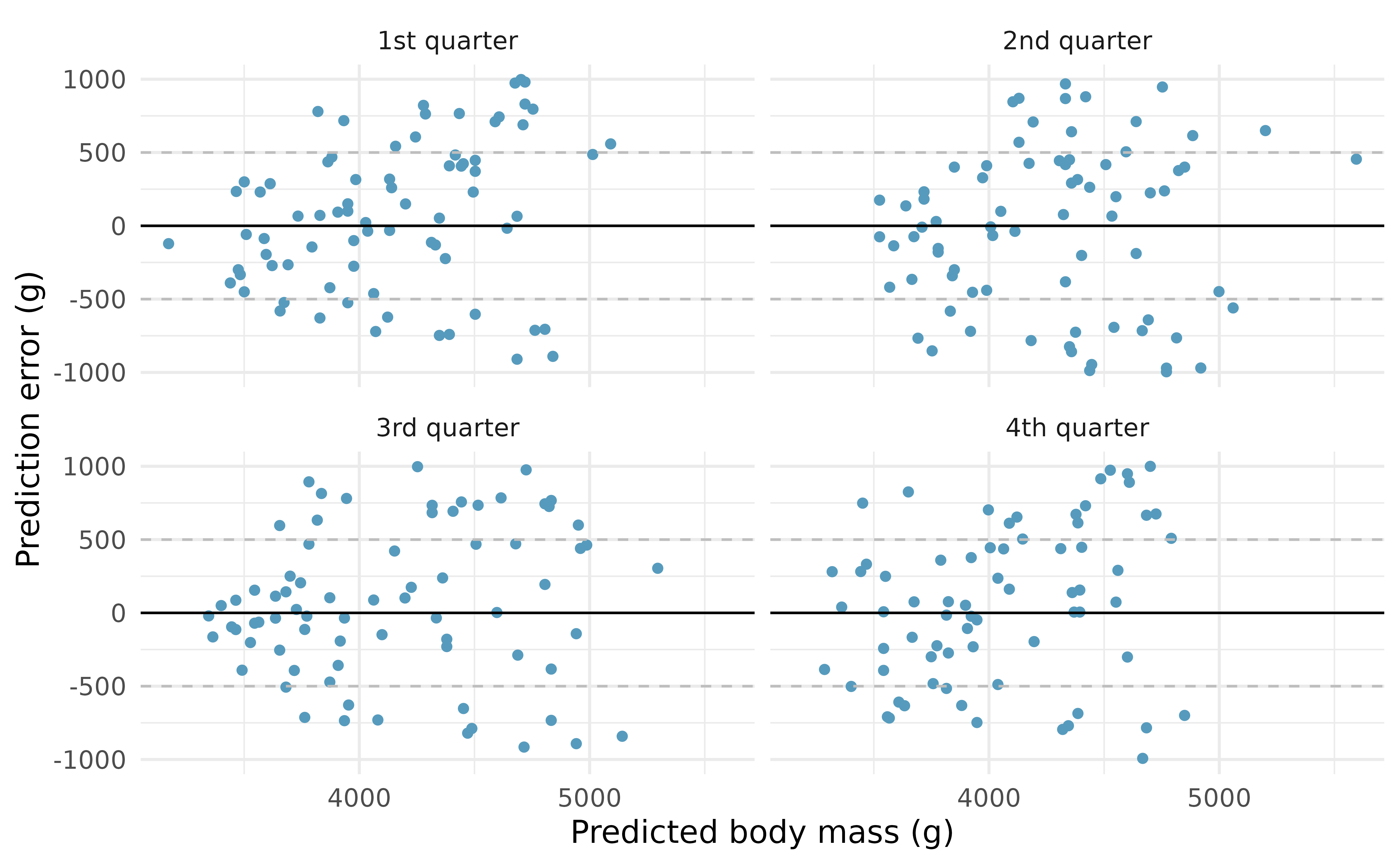
By repeating the process for each holdout quarter sample, the residuals from the model can be plotted against the predicted values. We see that the predictions are scattered which shows a good model fit but that the prediction errors vary \(\pm\) 1000g of the true body mass.
Figure 25.5: The smaller model. One quarter at a time, the data were removed from the model building, and the body mass of the removed penguins was predicted. The least squares regression model was fit independently of the removed penguins. The predictions of body mass are based on bill length only. The x-axis represents the predicted value, the y-axis represents the error (difference between predicted value and actual value).
The cross-validation SSE is the sum of squared error associated with the predictions. Let \(\hat{y}_{cv,i}\) be the prediction for the \(i^{th}\) observation where the \(i^{th}\) observation was in the hold-out fold and the other three folds were used to create the linear model. For the model using only bill_length_mm to predict body_mass_g, the CV SSE is 141,552,822.
Cross-validation SSE.
The prediction error from the cross-validated model can be used to calculate a single numerical summary of the model. The cross-validation SSE is the sum of squared cross-validation prediction errors.
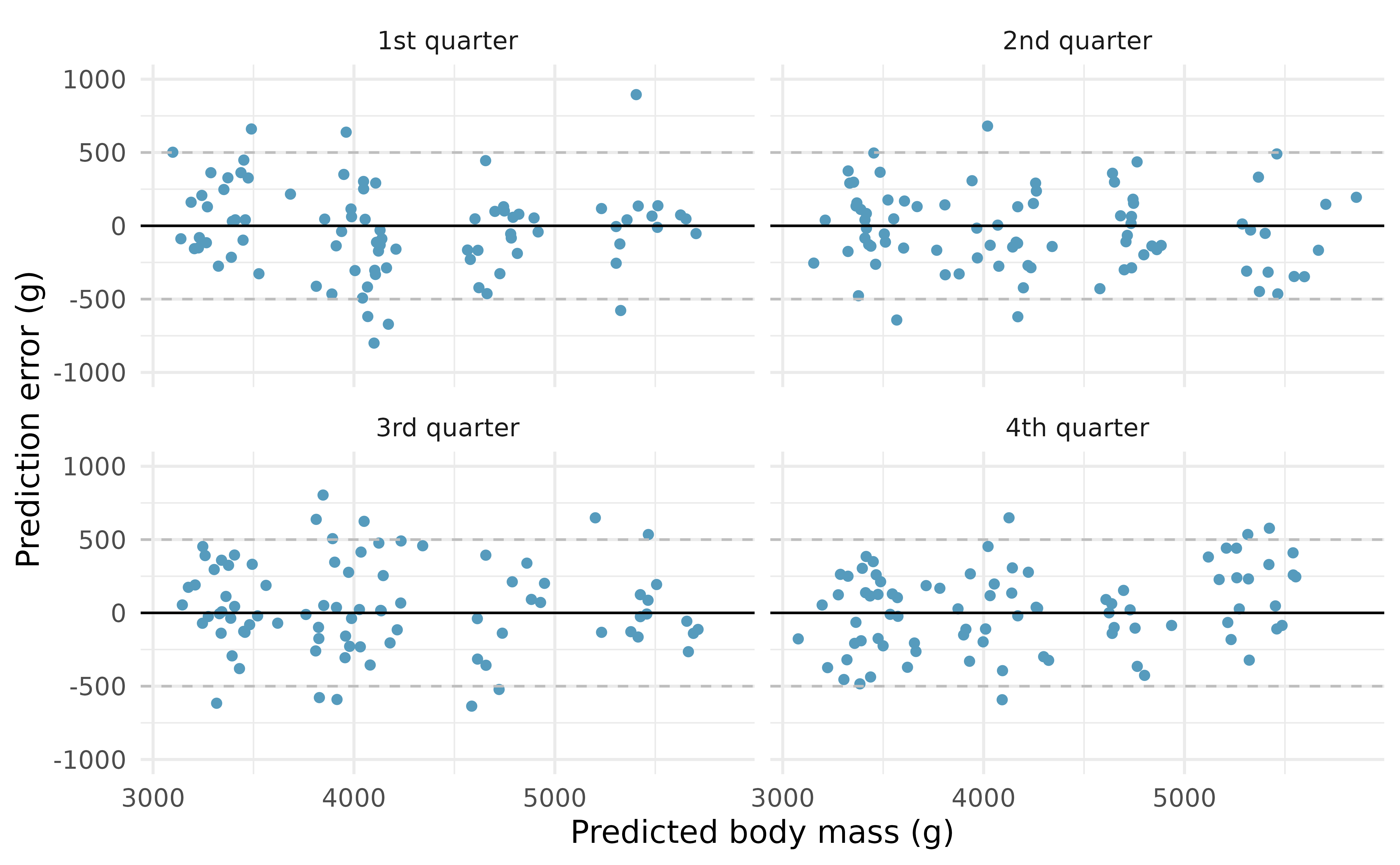
The same process is repeated for the larger number of explanatory variables. Note that the coefficients estimated for the first cross-validation model (in Figure 25.6) are slightly different from the estimates computed on the entire dataset (seen in Table 25.6). Figure 25.6 displays the cross-validation process for the multivariable model with a full set of residual plots given in Figure 25.7. Note that the residuals are mostly within \(\pm\) 500g, providing much more precise predictions for the independent body mass values of the individual penguins.
Figure 25.6: The larger model. The coefficients are estimated using the least squares model on 3/4 of the dataset with the five specified predictor variables. Predictions are made on the remaining 1/4 of the observations. The y-axis in the scatterplot represents the residual: true observed value minus the predicted value. Note that the predictions are independent of the estimated model coefficients.
Figure 25.7: The larger model. One quarter at a time, the data were removed from the model building, and the body mass of the removed penguins was predicted. The least squares regression model was fit independently of the removed penguins. The predictions of body mass are based on the set of five variables described in Table 25.6. The x-axis represents the predicted value, the y-axis represents the error (difference between predicted value and actual value).
Figure 25.5 shows that the independent predictions are centered around the true values (i.e., errors are centered around zero), but that the predictions can be as much as 1000g off when using only bill_length_mm to predict body_mass_g. On the other hand, when using bill_length_mm, bill_depth_mm, flipper_length_mm, sex, and species to predict body_mass_g, the prediction errors seem to be about half as big, as seen in Figure 25.7. For the model using bill_length_mm, bill_depth_mm, flipper_length_mm, sex, and species to predict body_mass_g, the CV SSE is 27,728,698 (as compared to a CV SSE of 141,552,822 for the smaller model). Consistent with visually comparing the two sets of residual plots, the sum of squared prediction errors is smaller for the model which uses more predictor variables. The model with more predictor variables seems like the better model (according to the cross-validated prediction errors criteria).
We have provided a very brief overview to and example of using cross-validation. Cross-validation is a computational approach to model building and model validation as an alternative to reliance on p-values. While p-values have a role to play in understanding model coefficients, throughout this text, we have continued to present computational methods that broaden statistical approaches to data analysis. Cross-validation will be used again in Chapter 26 with logistic regression. We encourage you to consider both standard inferential methods (such as p-values) and computational approaches (such as cross-validation) as you build and use multivariable models of all varieties.
25.4 Chapter review
25.4.1 Summary
Building on the modeling ideas from Chapter 8, we have now introduced methods for evaluating coefficients (based on p-values) and evaluating models (cross-validation). There are many important aspects to consider when working with multiple variables in a single model, and we have only glanced at a few topics. Remember, multicollinearity can make coefficient interpretation difficult. A topic not covered in this text but important for multiple regression models is interaction, and we hope that you learn more about how variables work together as you continue to build up your modeling skills.
25.4.2 Terms
We introduced the following terms in the chapter. If you’re not sure what some of these terms mean, we recommend you go back in the text and review their definitions. We are purposefully presenting them in alphabetical order, instead of in order of appearance, so they will be a little more challenging to locate. However, you should be able to easily spot them as bolded text.
cross-validation
multicollinearity
prediction error
inference on multiple linear regression
multiple predictors
predictor
25.5 Exercises
Answers to odd-numbered exercises can be found in Appendix A.25.
GPA, mathematical interval. A survey of 55 Duke University students asked about their GPA (gpa), number of hours they study weekly (studyweek), number of hours they sleep nightly (sleepnight), and whether they go out more than two nights a week (out_mt2). We use these data to build a model predicting GPA from the other variables. Summary of the model is shown below. Note that out_mt2 is 1 if the student goes out more than two nights a week, and 0 otherwise.3
term
estimate
std.error
statistic
p.value
(Intercept)
3.508
0.347
10.114
<0.0001
studyweek
0.002
0.004
0.400
0.6908
sleepnight
0.000
0.047
0.008
0.994
out_mt2
0.151
0.097
1.551
0.127
Calculate a 95% confidence interval for the coefficient of out_mt2 (go out more than two night a week) in the model, and interpret it in the context of the data.
Would you expect a 95% confidence interval for the slope of the remaining variables to include 0? Explain.
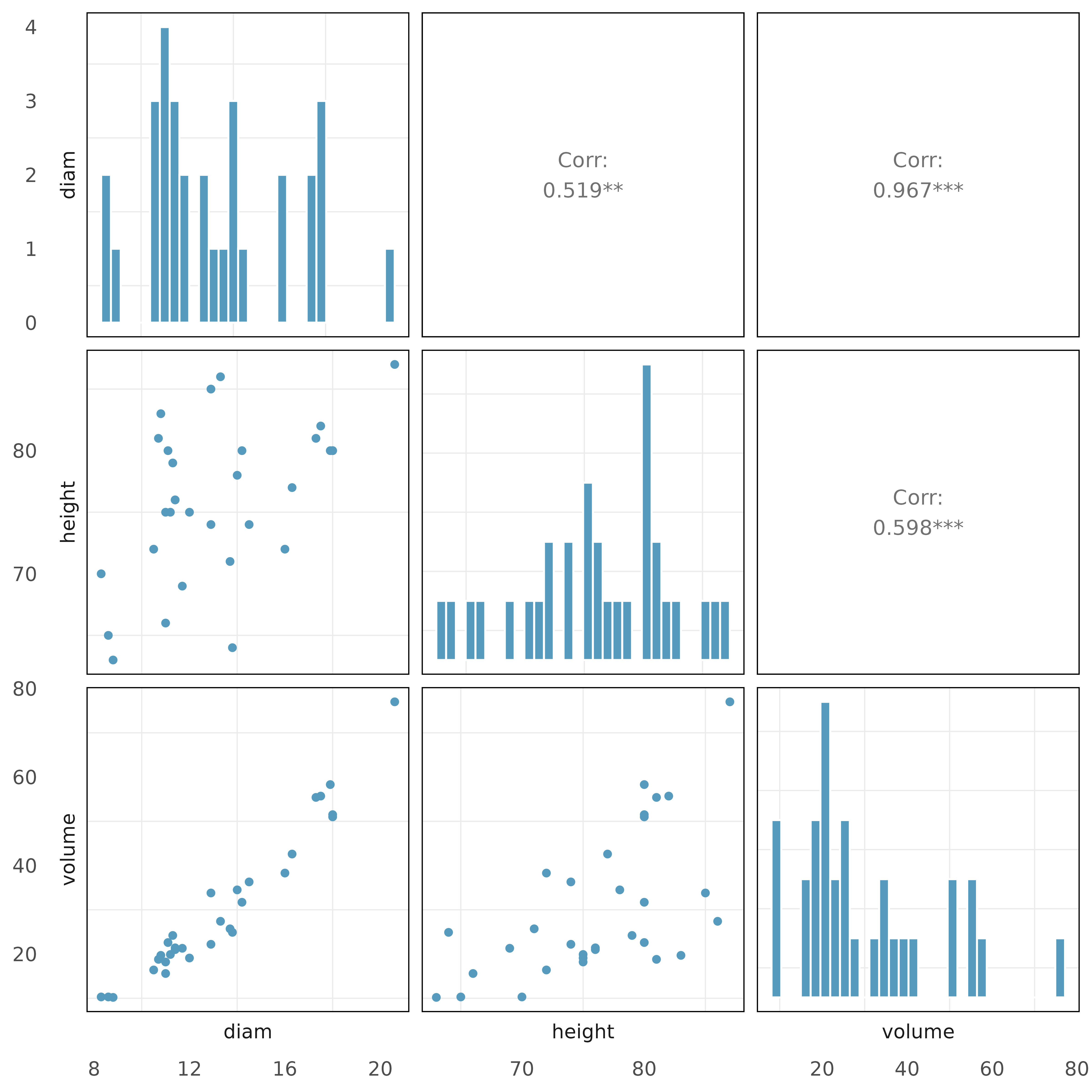
Cherry trees with collinear predictors. Timber yield is approximately equal to the volume of a tree, however, this value is difficult to measure without first cutting the tree down. Instead, other variables, such as height and diameter, may be used to predict a tree’s volume and yield. Researchers wanting to understand the relationship between these variables for black cherry trees collected data from 31 such trees in the Allegheny National Forest, Pennsylvania. Height is measured in feet, diameter in inches (at 54 inches above ground), and volume in cubic feet.4(Hand 1994)
The plots below describe the show the distribution of each of these variables (on the diagonal) as well as provide information on the pairwise correlations between them.
Also provided below are three regression model outputs: volume vs. diam, volume vs. height, and volume vs. height + diam.
term
estimate
std.error
statistic
p.value
(Intercept)
-36.94
3.365
-11.0
<0.0001
diam
5.07
0.247
20.5
<0.0001
term
estimate
std.error
statistic
p.value
(Intercept)
-87.12
29.273
-2.98
0.006
height
1.54
0.384
4.02
0.000
term
estimate
std.error
statistic
p.value
(Intercept)
-57.988
8.638
-6.71
<0.0001
height
0.339
0.130
2.61
0.0145
diam
4.708
0.264
17.82
<0.0001
There are three variables described in the figure, and each is paired with each other to create three different scatterplots. Rate the pairwise relationships from most correlated to least correlated.
When using only one variable to model a tree’s volume, is diameter a discernible predictor variable? Is height a discernible predictor variable? Explain.
When using both diameter and height to predict a tree’s volume, are both predictor variables still discernible? Explain.
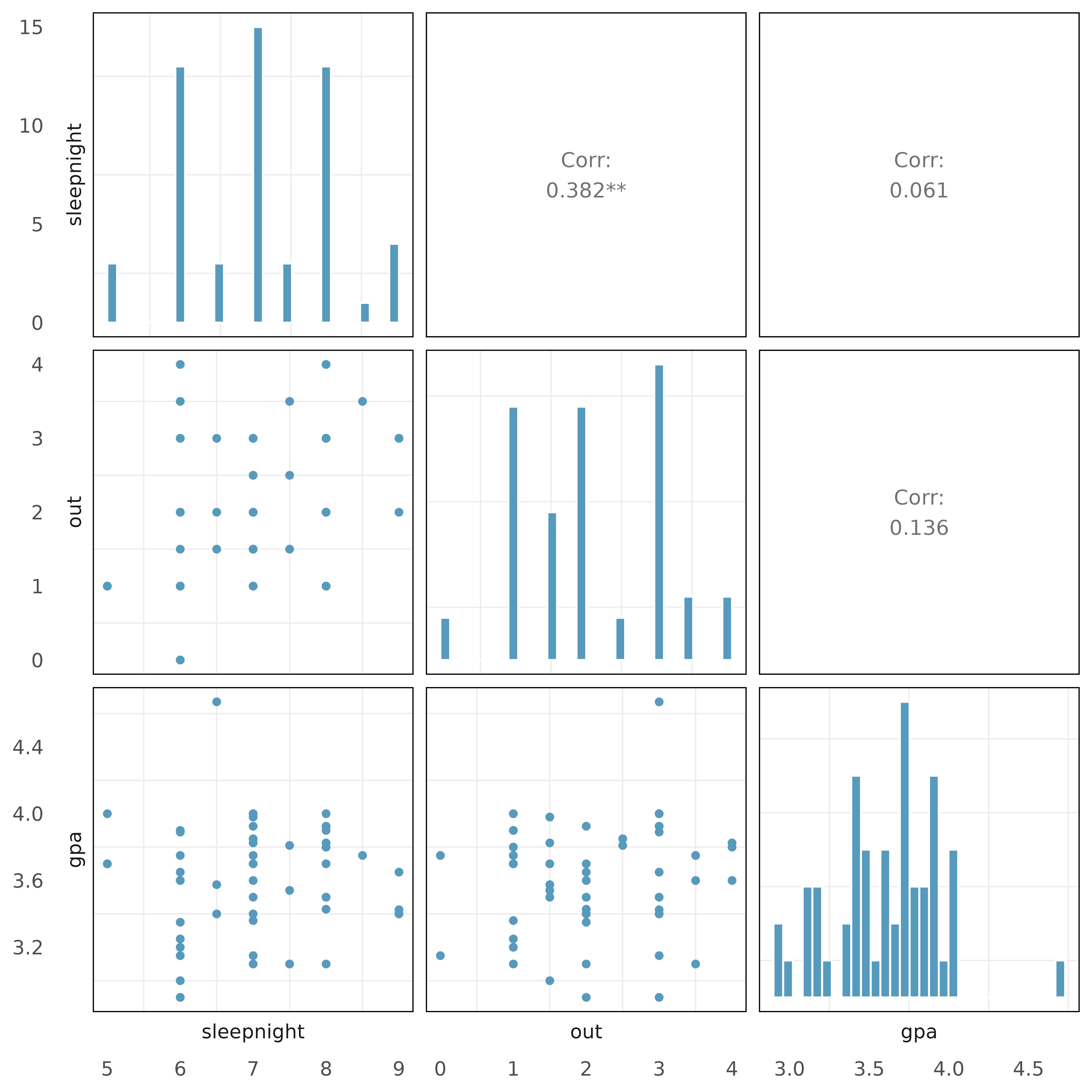
GPA, collinear predictors. In this exercise we work with data from a survey of 55 Duke University students who were asked about their GPA, number of hours they sleep nightly, and number of nights they go out each week.
The plots below describe the show the distribution of each of these variables (on the diagonal) as well as provide information on the pairwise correlations between them.
Also provided below are three regression model outputs: gpa vs. out, gpa vs. sleepnight, and gpa vs. out + sleepnight.
term
estimate
std.error
statistic
p.value
(Intercept)
3.504
0.106
33.011
<0.0001
out
0.045
0.046
0.998
0.3229
term
estimate
std.error
statistic
p.value
(Intercept)
3.46
0.318
10.874
<0.0001
sleepnight
0.02
0.045
0.445
0.6583
term
estimate
std.error
statistic
p.value
(Intercept)
3.483
0.320
10.888
<0.0001
out
0.044
0.050
0.886
0.3796
sleepnight
0.003
0.048
0.072
0.9432
There are three variables described in the figure, and each is paired with each other to create three different scatterplots. Rate the pairwise relationships from most correlated to least correlated.
When using only one variable to model gpa, is out a discernible predictor variable? Is sleepnight a discernible predictor variable? Explain.
When using both out and sleepnight to predict gpa in a multiple regression model, are either of the variables discernible? Explain.
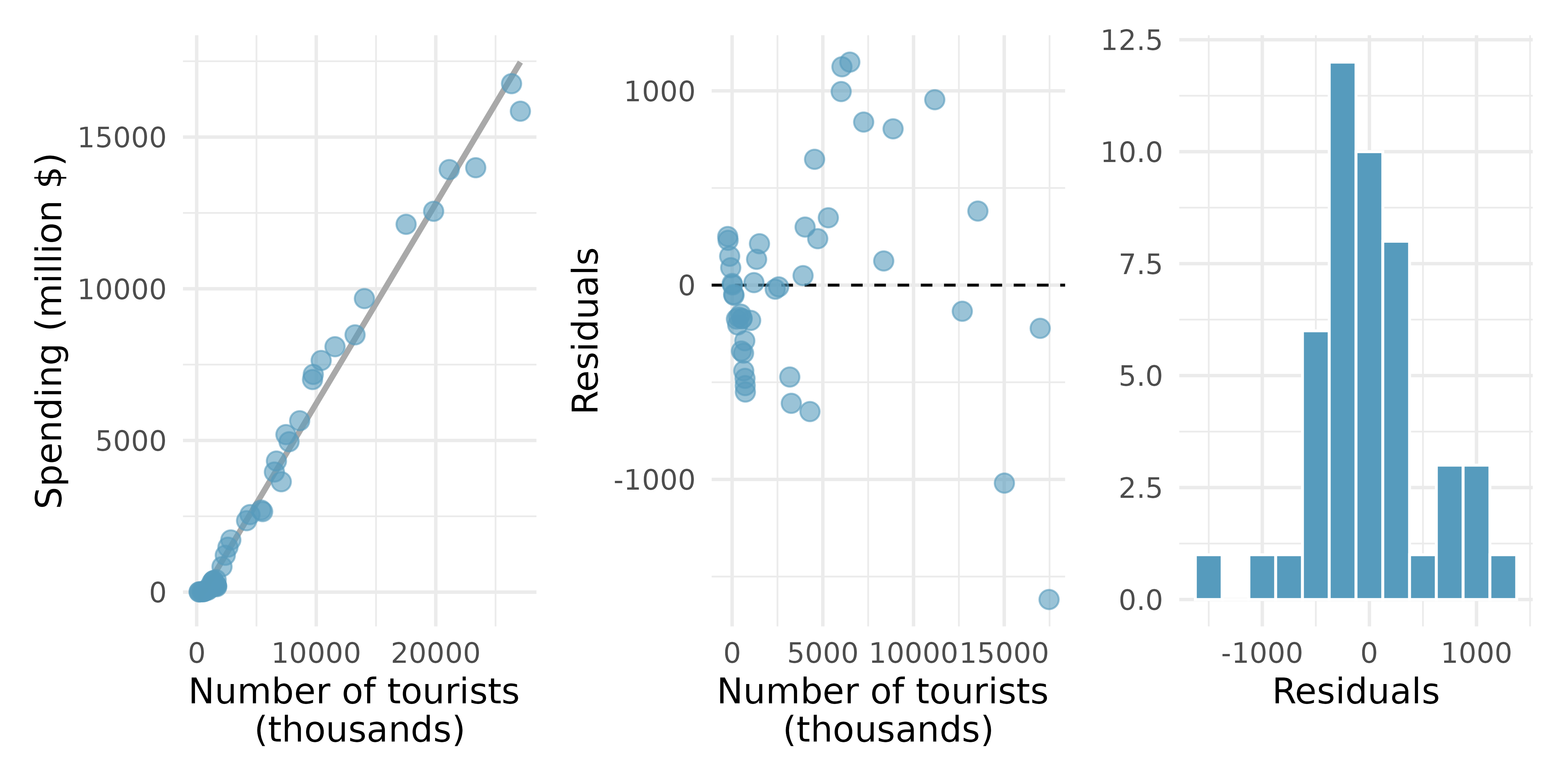
Tourism spending. The Association of Turkish Travel Agencies reports the number of foreign tourists visiting Turkey and tourist spending by year. Three plots are provided: scatterplot showing the relationship between these two variables along with the least squares fit, residuals plot, and histogram of residuals.5
Describe the relationship between number of tourists and spending.
What are the predictor and the outcome variables?
Why might we want to fit a regression line to these data?
Do the data meet the LINE conditions required for fitting a least squares line? In addition to the scatterplot, use the residual plot and histogram to answer this question.
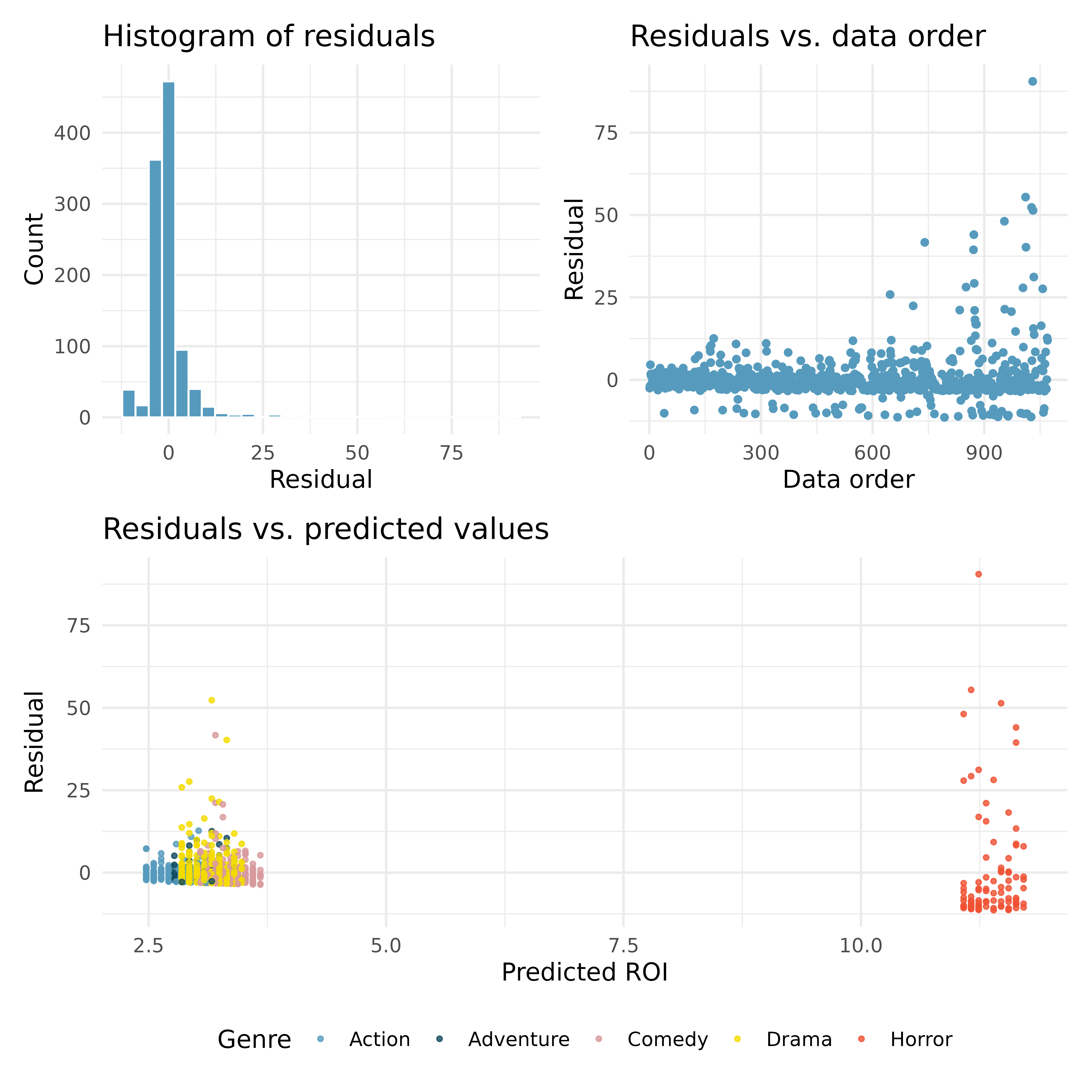
Movie returns. A FiveThirtyEight.com article reports that “Horror movies get nowhere near as much draw at the box office as the big-time summer blockbusters or action/adventure movies, but there’s a huge incentive for studios to continue pushing them out. The return-on-investment potential for horror movies is absurd.” To investigate how the return-on-investment (ROI) compares between genres and how this relationship has changed over time, an introductory statistics student fit a linear regression model to predict the ratio of gross revenue of movies to the production costs from genre and release year for 1,070 movies released between 2000 and 2018. Using the plots given below, determine if this regression model is appropriate for these data. In particular, use the residual plot to check the LINE conditons. (FiveThirtyEight 2015)
Difficult encounters. A study was conducted at a university outpatient primary care clinic in Switzerland to identify factors associated with difficult doctor-patient encounters. The data consist of 527 patient encounters, conducted by the 27 medical residents employed at the clinic. After each encounter, the attending physician completed two questionnaires: the Difficult Doctor Patient Relationship Questionnaire (DDPRQ-10) and the patient’s vulnerability grid (PVG).
A higher score on the DDPRQ-10 indicates a more difficult encounter. The maximum possible score is 60 and encounters with score 30 and higher are considered difficult.
A model was fit for the association of DDPRQ-10 score with features of the attending physician: age, sex (identify as male or not), and years of training.
term
estimate
std.error
statistic
p.value
(Intercept)
30.594
2.886
10.601
<0.0001
age
-0.016
0.104
-0.157
0.876
sexMale
-0.535
0.781
-0.686
0.494
yrs_train
0.096
0.215
0.445
0.656
The intercept of the model is 30.594. What is the age, sex, and years of training of a physician whom this model would predict to have a DDPRQ-10 score of 30.594.
Is there evidence of a discernible association between DDPRQ-10 score and any of the physician features?
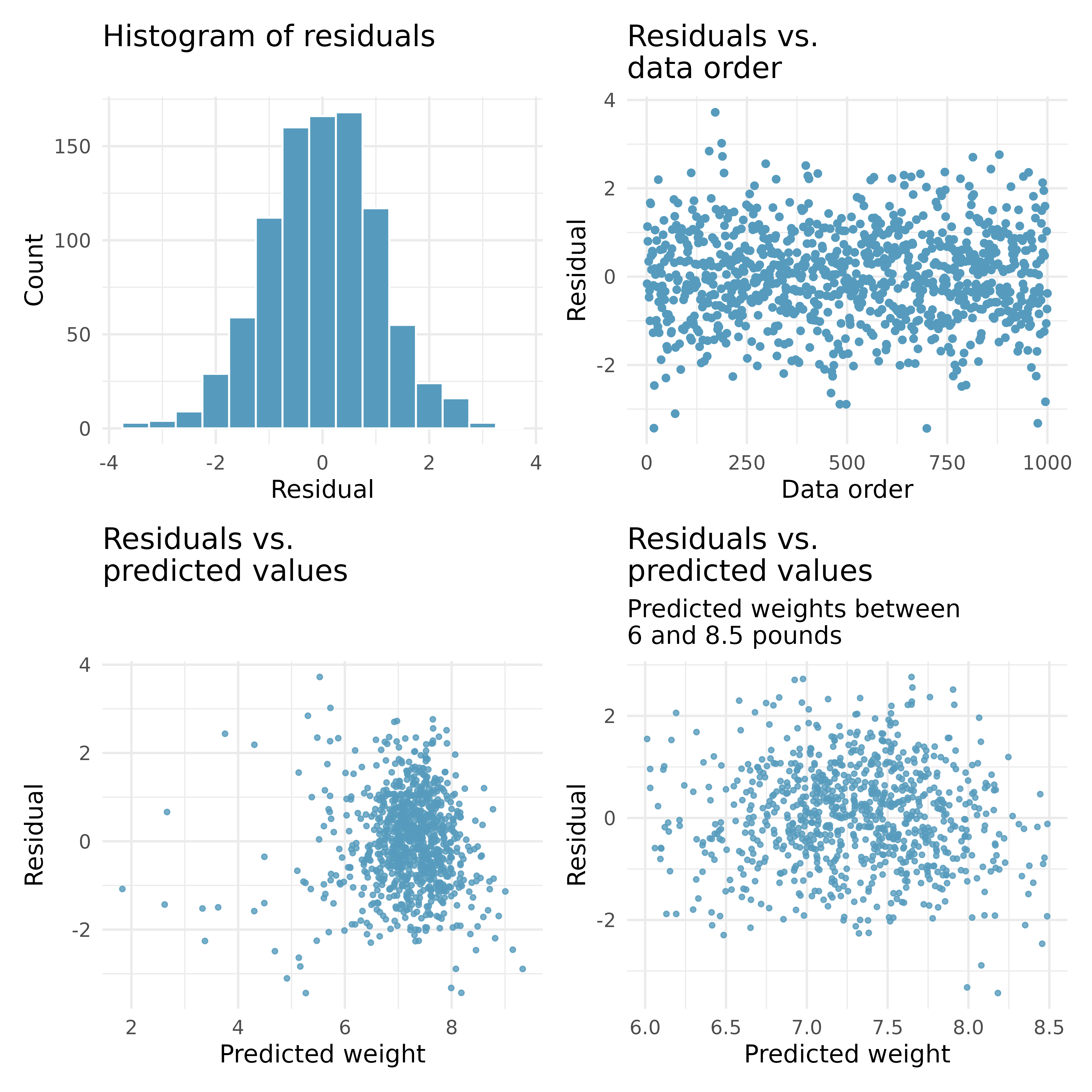
Baby’s weight, mathematical test. US Department of Health and Human Services, Centers for Disease Control and Prevention collect information on births recorded in the country. The data used here are a random sample of 1,000 births from 2014. Here, we study the relationship between smoking and weight of the baby. The variable smoke is coded 1 if the mother is a smoker, and 0 if not. The summary table below shows the results of a linear regression model for predicting the average birth weight of babies, measured in pounds, based on the smoking status of the mother.6(ICPSR 2014)
term
estimate
std.error
statistic
p.value
(Intercept)
-3.82
0.57
-6.73
<0.0001
weeks
0.26
0.01
18.93
<0.0001
mage
0.02
0.01
2.53
0.0115
sexmale
0.37
0.07
5.30
<0.0001
visits
0.02
0.01
2.09
0.0373
habitsmoker
-0.43
0.13
-3.41
7e-04
Also shown below are a series of diagnostics plots.
Determine if the conditions for doing inference based on mathematical models with these data are met using the diagnostic plots above. If not, describe how to proceed with the analysis.
Using the regression output, evaluate whether the true slope of habit (i.e., whether the mother is a smoker) is different than 0, given the other variables in the model. State the null and alternative hypotheses, report the p-value (using a mathematical model), and state your conclusion.
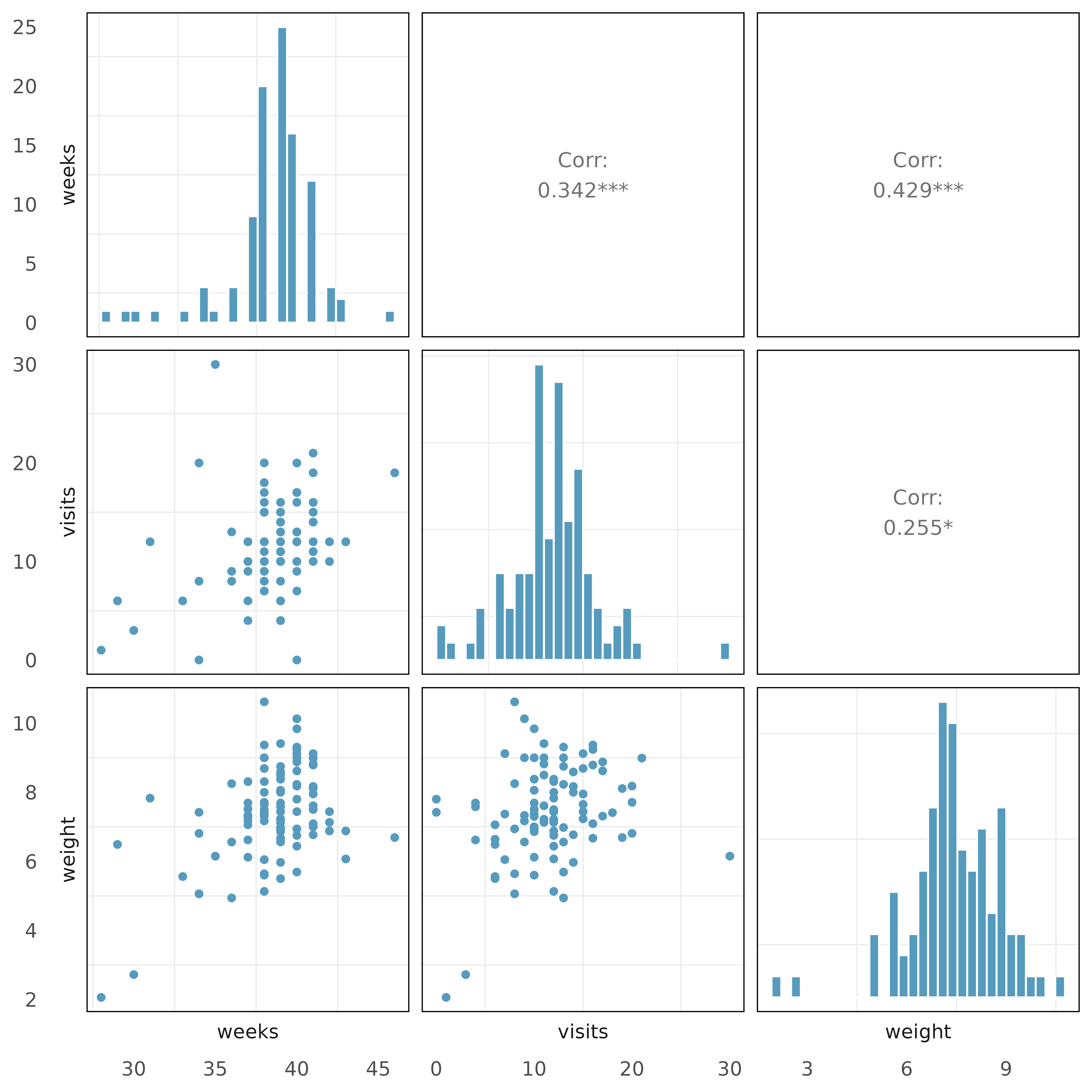
Baby’s weight with collinear predictors. In this exercise we study the relationship between the weight of the baby and two explanatory variables: number of weeks of gestation and number of pregnancy hospital visits. (ICPSR 2014)
The plots below describe the show the distribution of each of these variables (on the diagonal) as well as provide information on the pairwise correlations between them.
Also provided below are three regression model outputs: weight vs. weeks, weight vs. visits, and weight vs. weeks + visits.
term
estimate
std.error
statistic
p.value
(Intercept)
-0.83
1.76
-0.47
0.6395
weeks
0.21
0.05
4.70
<0.0001
term
estimate
std.error
statistic
p.value
(Intercept)
6.56
0.36
18.36
<0.0001
visits
0.08
0.03
2.61
0.0105
term
estimate
std.error
statistic
p.value
(Intercept)
-0.44
1.78
-0.25
0.81
weeks
0.19
0.05
4.00
0.00
visits
0.04
0.03
1.26
0.21
There are three variables described in the figure, and each is paired with each other to create three different scatterplots. Rate the pairwise relationships from most correlated to least correlated.
When using only one variable to model the baby’s weight, is weeks a discernible predictor variable? Is visits a discernible predictor variable? Explain.
When using both visits and weeks to predict the baby’s weight, are both predictor variables still discernible? Explain.
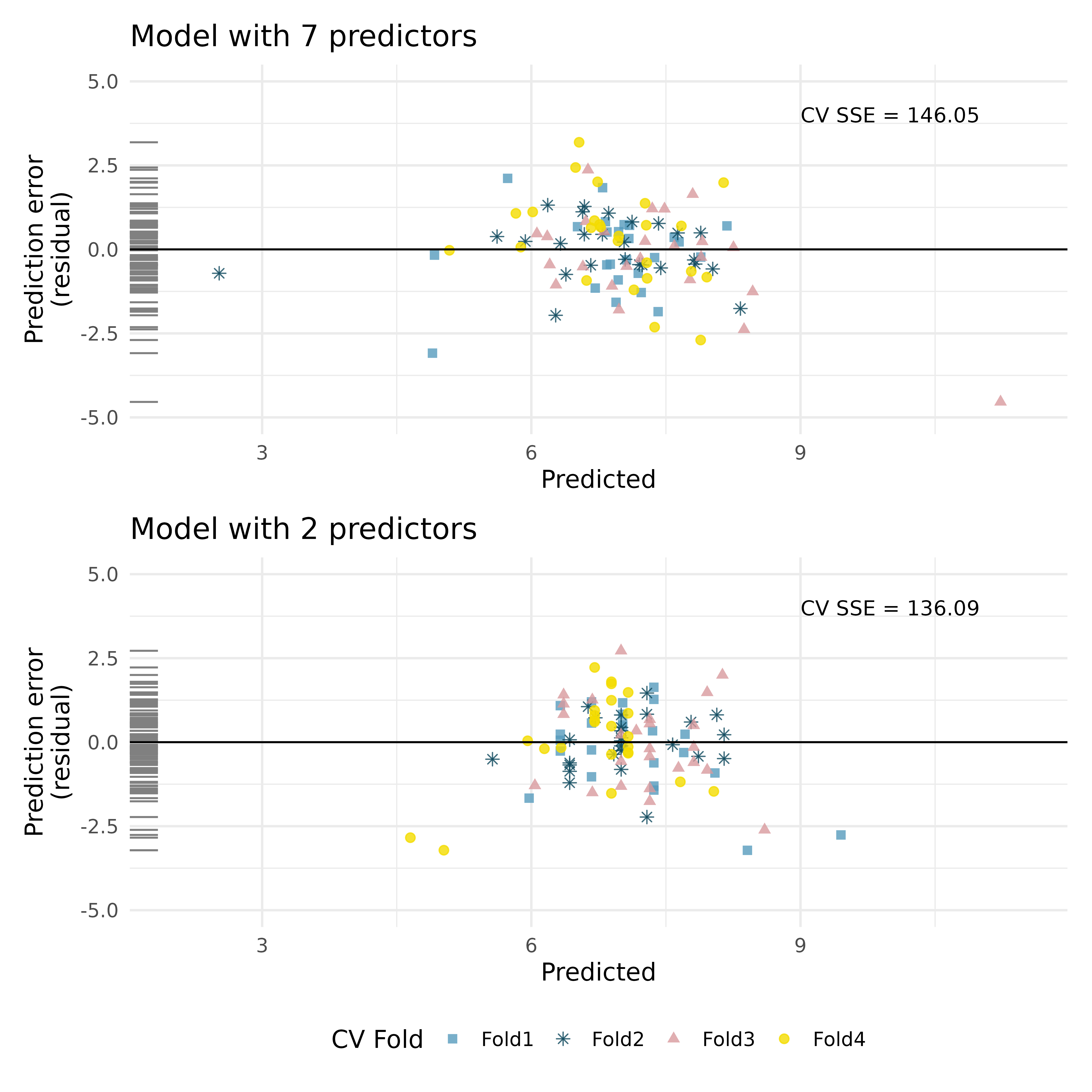
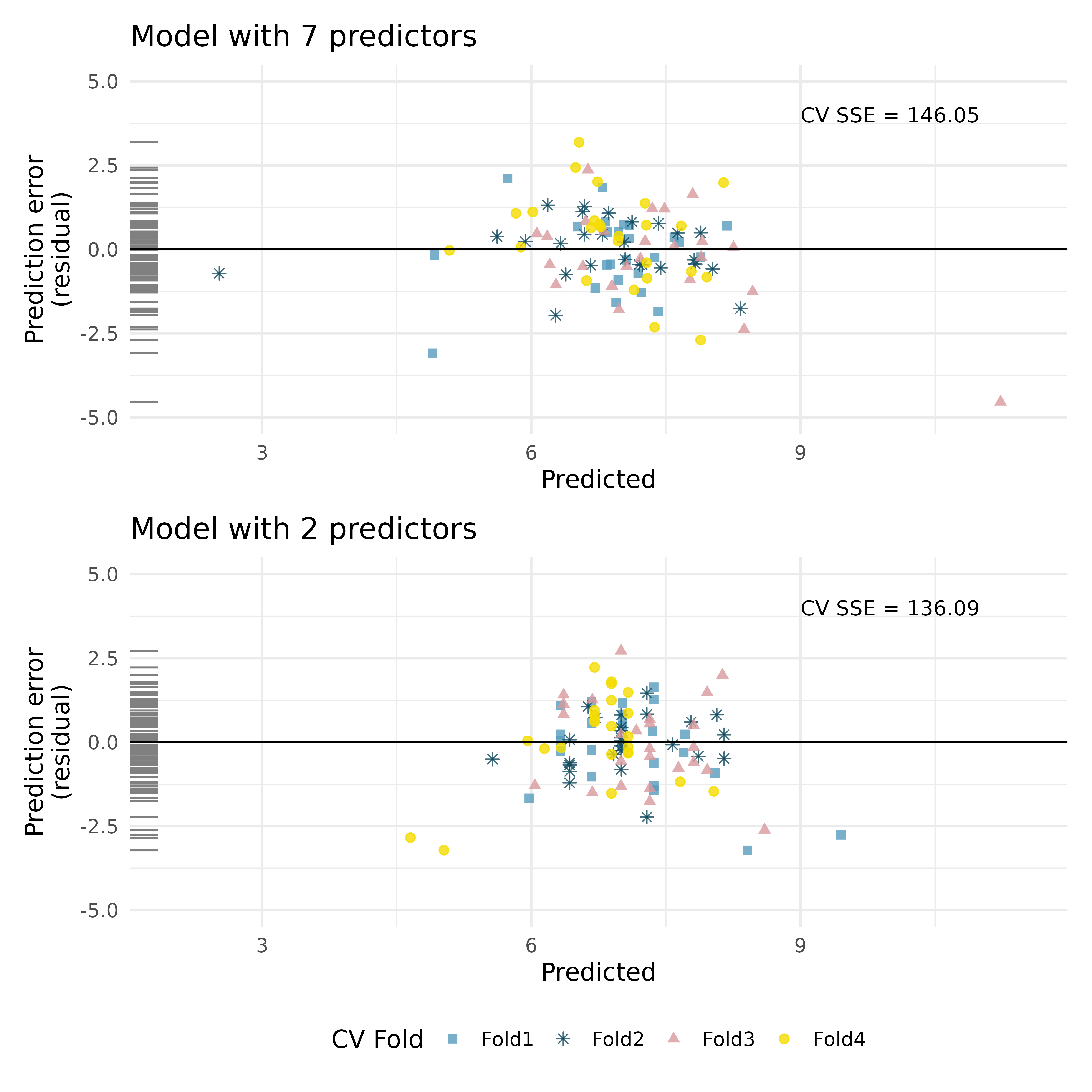
Baby’s weight, cross-validation. Using a random sample of 1,000 US births from 2014, we study the relationship between the weight of the baby and various explanatory variables. (ICPSR 2014)
The plots below describe prediction errors associated with two different models designed to predict weight of baby at birth; one model uses 7 predictors, one model uses 2 predictors. Using 4-fold cross-validation, the data were split into 4 folds. Three of the folds estimate the \(\beta_i\) parameters using \(b_i\), and the model is applied to the held out fold for prediction. The process was repeated 4 times (each time holding out one of the folds).
In the first graph, note the point at roughly (predicted = 11 and error = -4). Estimate the observed and predcited value for that observation.
Using the same point, describe which cross-validation fold(s) were used to build its prediction model.
For the plot on the top, for one of the cross-validation folds, how many coefficients were estimated in the linear model? For the plot on the bottom, for one of the cross-validation folds, how many coefficients were estimated in the linear model?
Do the values of the residuals (along the y-axis, not the x-axis) seem markedly different for the two models? Explain.
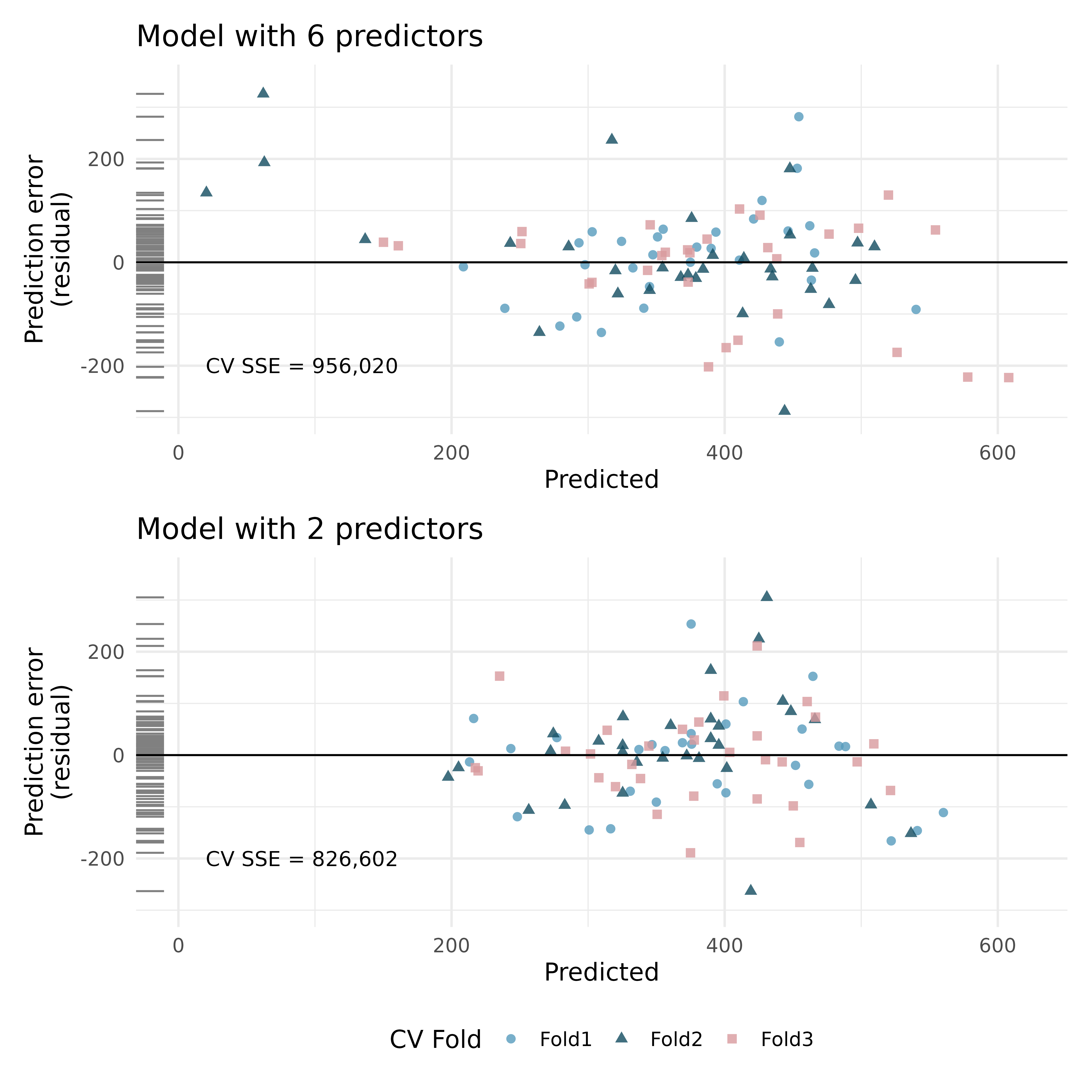
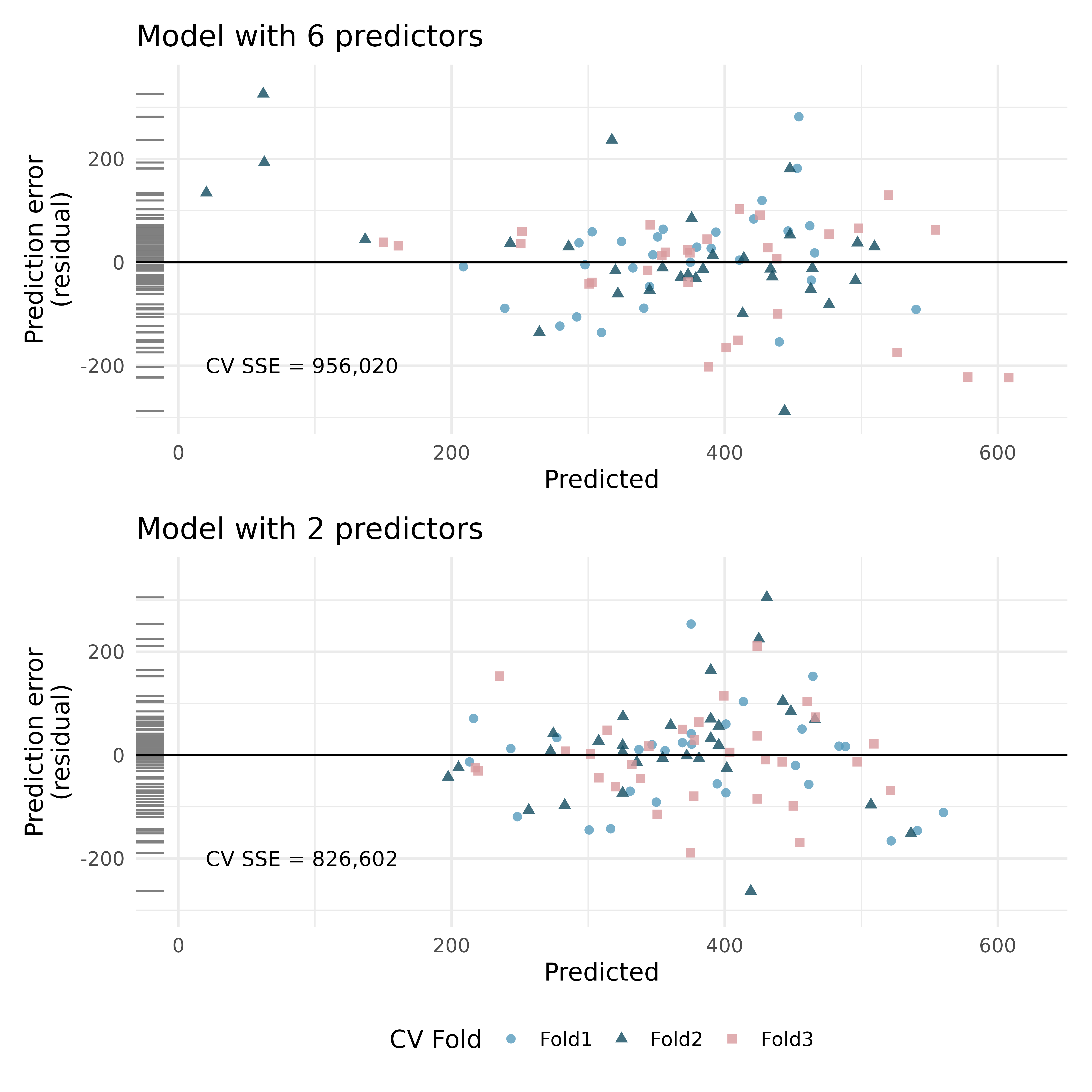
RailTrail, cross-validation. The Pioneer Valley Planning Commission (PVPC) collected data north of Chestnut Street in Florence, MA for ninety days from April 5, 2005 to November 15, 2005. Data collectors set up a laser sensor, with breaks in the laser beam recording when a rail-trail user passed the data collection station.7
The plots below describe prediction errors associated with two different models designed to predict the volume of riders on the RailTrail; one model uses 6 predictors, one model uses 2 predictors. Using 3-fold cross-validation, the data were split into 3 folds. Three of the folds estimate the \(\beta_i\) parameters using \(b_i\), and the model is applied to the held out fold for prediction. The process was repeated 4 times (each time holding out one of the folds).
In the second graph, note the point at roughly (predicted = 400 and error = 100). Estimate the observed and predcited value for that observation.
Using the same point, describe which cross-validation fold(s) were used to build its prediction model.
For the plot on the top, for one of the cross-validation folds, how many coefficients were estimated in the linear model? For the plot on the bottom, for one of the cross-validation folds, how many coefficients were estimated in the linear model?
Do the values of the residuals (along the y-axis, not the x-axis) seem markedly different for the two models? Explain.
Baby’s weight, cross-validation to choose model. Using a random sample of 1,000 US births from 2014, we study the relationship between the weight of the baby and various explanatory variables. (ICPSR 2014)
The plots below describe prediction errors associated with two different models designed to predict weight of baby at birth; one model uses 7 predictors, one model uses 2 predictors. Using 4-fold cross-validation, the data were split into 4 folds. Three of the folds estimate the \(\beta_i\) parameters using \(b_i\), and the model is applied to the held out fold for prediction. The process was repeated 4 times (each time holding out one of the folds).
Using the spread of the points (in the y-direction), which model should be chosen for a final report on these data? Explain.
Using the summary statistic (CV SSE), which model should be chosen for a final report on these data? Explain.
Why would the model with more predictors fit the data less closely than the model with only two predictors?
RailTrail, cross-validation to choose model. The Pioneer Valley Planning Commission (PVPC) collected data north of Chestnut Street in Florence, MA for ninety days from April 5, 2005 to November 15, 2005. Data collectors set up a laser sensor, with breaks in the laser beam recording when a rail-trail user passed the data collection station.
The plots below describe prediction errors associated with two different models designed to predict the volume of riders on the RailTrail; one model uses 6 predictors, one model uses 2 predictors. Using 3-fold cross-validation, the data were split into 3 folds. Three of the folds estimate the \(\beta_i\) parameters using \(b_i\), and the model is applied to the held out fold for prediction. The process was repeated 4 times (each time holding out one of the folds).
Using the spread of the points (in the y-direction), which model should be chosen for a final report on these data? Explain.
Using the summary statistic (CV SSE), which model should be chosen for a final report on these data? Explain.
Why would the model with more predictors fit the data less closely than the model with only two predictors?
Figure 25.1: A sample of coins with 16 total coins, 10 low coins, and a net worth of $1.90.Figure 25.2: Plot describing the total amount of money (USD) as a function of the number of coins and the number of low coins. As you might expect, the total amount of money is more highly postively correlated with the total number of coins than with the number of low coins.Figure 25.3: The dataset is broken into k folds (here k = 4). One at a time, a model is built using k-1 of the folds, and predictions are calculated on the single held out sample which will be completely independent of the model estimation.Figure 25.4: The smaller model. The coefficients are estimated using the least squares model on 3/4 of the dataset with only a single predictor variable. Predictions are made on the remaining 1/4 of the observations. The y-axis in the scatterplot represents the residual: true observed value minus the predicted value. Note that the predictions are independent of the estimated model coefficients.Figure 25.5: The smaller model. One quarter at a time, the data were removed from the model building, and the body mass of the removed penguins was predicted. The least squares regression model was fit independently of the removed penguins. The predictions of body mass are based on bill length only. The x-axis represents the predicted value, the y-axis represents the error (difference between predicted value and actual value).Figure 25.6: The larger model. The coefficients are estimated using the least squares model on 3/4 of the dataset with the five specified predictor variables. Predictions are made on the remaining 1/4 of the observations. The y-axis in the scatterplot represents the residual: true observed value minus the predicted value. Note that the predictions are independent of the estimated model coefficients.Figure 25.7: The larger model. One quarter at a time, the data were removed from the model building, and the body mass of the removed penguins was predicted. The least squares regression model was fit independently of the removed penguins. The predictions of body mass are based on the set of five variables described in Table 25.6. The x-axis represents the predicted value, the y-axis represents the error (difference between predicted value and actual value).
Gorman, K. B., T. D. Williams, and W. R. Fraser. 2014. “Ecological sexual dimorphism and environmental variability within a community of Antarctic penguins (genus Pygoscelis).”PloS One 9 (3): e90081. https://doi.org/doi.org/10.1371/journal.pone.0090081.
Hand, D. J. 1994. A handbook of small data sets. Chapman & Hall/CRC.
ICPSR. 2014. “United States Department of Health and Human Services. Centers for Disease Control and Prevention. National Center for Health Statistics. Natality Detail File, 2014 United States. Inter-University Consortium for Political and Social Research, 2016-10-07.”https://doi.org/10.3886/ICPSR36461.v1.
In previous sections, the term explanatory variable was used instead of predictor. The words are synonymous and are used separately in the different sections to be consistent with how most analysts use them: explanatory variable for testing, predictor for modeling.↩︎
In all honesty, this particular dataset is fabricated, and the original idea for the problem comes from Jeff Witmer at Oberlin College.↩︎
The gpa data used in this exercise can be found in the openintro R package.↩︎
The cherry data used in this exercise can be found in the openintro R package.↩︎
The tourism data used in this exercise can be found in the openintro R package.↩︎
The births14 data used in this exercise can be found in the openintro R package.↩︎
The RailTrail data used in this exercise can be found in the mosaicData R package.↩︎